S3のGlacierストレージクラスにバックアップしていたデータをダウンロードするためのスクリプトを書きました。以下のようなたくさんのファイルをダウンロードするのに向いてます。
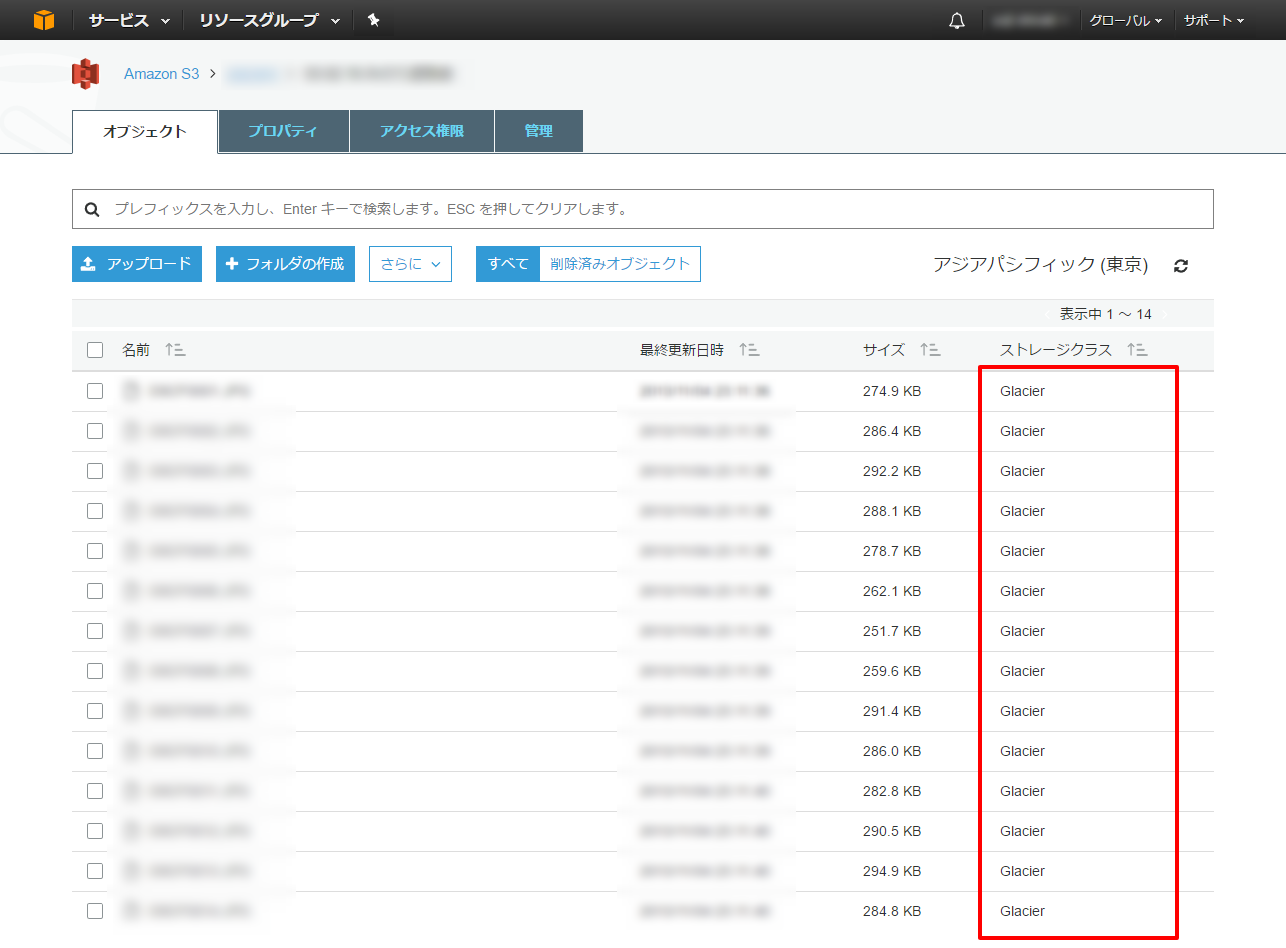
ハマりどころとしては、AWSにはAmazon GlacierというS3のGlacierストレージクラスと同じような独立サービスがあったところです。 この両者はファイルやAPIの取り扱いが異なるため、正しい情報を見つけるのに大変苦労しました。
ではいってみましょう。
環境
- Windows10
- Python3.5.2
- boto3
- aws-cli1.11.70
事前準備
今回のスクリプトはawscliがインストールされている前提です。まだインストールされていない方はあらかじめインストールとアカウントの設定を済ませてください。
またAWSのAPIを利用するためAWS SDK for Python (Boto3)を利用しています。pipでインストールできます。
pip install boto3手順
- S3のAPIでダウンロードしたいファイルに対してrestoreのリクエストを出す
- 一定時間ごとにポーリングしてrestoreリクエストの処理が終わっていたらファイルをダウンロードする
コード
コードはこんな感じです。
# -*- coding:utf-8 -*-
import boto3
import os
import re
import time
from datetime import datetime
TARGET_BUCKET_NAME = '[type your bucket name]'
TARGET_TYPE = 'DIR' # or FILE
TARGET_DIR_NAME = ''
TARGET_FILE_NAME = ''
DOWNLOADED_DIR = './downloaded/'
POLLING_TIME = 7200 # 2.0h
s3 = boto3.resource('s3')
bucket = s3.Bucket(TARGET_BUCKET_NAME)
def main():
print(datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
# DOWNLOADED_DIRの有無を確認し、なければ作成
print('check and create download dir.')
if os.path.exists(DOWNLOADED_DIR) is False:
os.mkdir(DOWNLOADED_DIR)
# グローバル変数チェック
print('variables check.')
if TARGET_BUCKET_NAME == '':
raise ValueError('TARGET_BUCKET_NAMEが空です')
if TARGET_TYPE not in ['DIR', 'FILE']:
raise ValueError('TARGET_TYPEが正しくありません')
if TARGET_TYPE == 'DIR' and (TARGET_DIR_NAME == '' or TARGET_DIR_NAME is None):
raise ValueError('TARGET_DIR_NAMEが正しくありません')
if TARGET_TYPE == 'FILE' and (TARGET_FILE_NAME == '' or TARGET_FILE_NAME is None):
raise ValueError('TARGET_FILE_NAMEが正しくありません')
# 指定条件に合致するオブジェクト(ファイル)の情報を取得
print('search target files.')
target_objs = {}
for obj_sum in bucket.objects.all():
obj = bucket.Object(obj_sum.key)
obj_dir_path = re.sub(r'(.*)\/.*', r'\1', obj_sum.key)
obj_first_dir = re.sub(r'\/.*', '', obj_sum.key)
obj_file_name = re.sub(r'.*\/', '', obj_sum.key)
is_target = False
if TARGET_TYPE == 'DIR':
if obj_first_dir == TARGET_DIR_NAME and obj_file_name is not '':
is_target = True
elif TARGET_TYPE == 'FILE':
if obj_file_name == TARGET_FILE_NAME:
is_target = True
if is_target:
target_objs[obj_sum.key] = {
'dir_path' : obj_dir_path
, 'storage_class' : obj.storage_class
, 'status' : ''
}
# 各ファイルのkeyに含まれるディレクトリ情報を抽出してDOWNLOADED_DIR内に作成
dirs = [v['dir_path'] for k, v in target_objs.items() ]
dirs = list(set(dirs))
for d in dirs:
os.makedirs(DOWNLOADED_DIR + d, exist_ok=True)
# ダウンロードリクエスト & ポーリングでダウンロード
print('start polling.')
while is_complete(target_objs) is False:
print('='*80)
print(datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
for key, attrs in target_objs.items():
if attrs['storage_class'] == 'GLACIER':
obj = bucket.Object(key)
if obj.restore is None:
# ここがrestoreのリクエスト部分
obj.restore_object(
RequestPayer = 'requester',
RestoreRequest = {
'Days' : 1,
'GlacierJobParameters': {
'Tier' : 'Standard'
}
}
)
elif 'ongoing-request="true"' in obj.restore:
attrs['status'] = 'in_progress'
elif 'ongoing-request="false"' in obj.restore:
obj.download_file(DOWNLOADED_DIR + key)
attrs['status'] = 'complete'
print('{:<150}{:<10}{:<10}'.format(key[:120], attrs['storage_class'], attrs['status']))
if is_complete(target_objs) is False:
print('sleep.')
time.sleep(POLLING_TIME)
else:
continue
print("END")
print(datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
def is_complete(objs):
ret = True
for k, v in objs.items():
if v['status'] is not 'complete':
ret = False
return ret
if __name__ == '__main__':
main()使い方
使う時にはTARGET_DIRかTARGET_FILEにダウンロードしたいディレクトリ、もしくはファイルの情報を記載して下さい。もしディレクトリごとダウンロードする場合はTARGET_TYPEをDIRに、ファイルをダウンロードする場合はTARGET_TYPEをFILEとしてください。両方同時に指定することはできません。
また上記のスクリプトではPOLLING_TIMEが7200秒、すなわち2時間に指定されています。Glacierはだいたい4時間でrestoreが完了するので、restoreリクエスト出す→一回ポーリングを空振る→二回目のポーリングでダウンロード完了となります。空振るのが嫌であればPOLLING_TIMEを14400以上にすることをお勧めします。
注意事項
Glacierからの復元については料金設計に重要なポイントがあります。具体的にはリンク先を読んでいただければと思いますが、くれぐれもご注意ください。
なお、今回紹介したスクリプトの使用は自己責任でお願いします。これを利用した方が何かしらの損失を被っても責任を負いかねますのであらかじめご了承ください。
参考
以上です。